Semi-supervised Machine Learning for Countering Concept Drift in Security Applications
10 October 2011
Abstract of the Project
Our project is initially motivated by an access control system making use of Machine Learning to increase security and help with the potential shortcomings of rule based access control system such as missing or conflicting rules. We take Figure 1 as our access control paradigm. Alice is the requester and Bob is the (security) supervisor. The rules component are a traditional access control system containing rules Bob has set, while the advisor component is a Machine Learning based system that assesses Alice’s request and is the focus of this research. Bob is responsible for the resource being controlled although it might not directly belong to him (Bob might be the security supervisor in a hospital and the resource being controlled might be a patient’s health record for instance). When Alice requests resource R the first decision comes to Bob. If Bob is available, the access is granted based on his decision and this decision propagates to the advisor component through the rules component which in turn learns from it. Usually Bob is not available thus Alice’s request is directly made to the rules component. The rules component works closely with the advisor component, actual rules in the component can explicitly refer to the advisor such as: if conflict in rules then trust advisor or if no rule then trust advisor which could be set as a default rule. The access is granted based on the rules component, and the final decision propagates to the advisor component that learns from this decision. The advisor component can potentially do two actions, it can alert Bob by asking him a second opinion on an access, in the case its answer differs from rules component, and it can also directly take feedback from Bob which can correct an access as valid or invalid if it was not classified properly. The advantage of adding such an advisor component that maintains a model of normal operations to an access control system is two fold. First, it enhances a traditional access control system by being able to spot abnormal operations resulting of incomplete/erroneous rules in the rules component or malicious requests. Second, it can be trained by examples rather than by general rules which can be harder to formulate. Moreover it is nearly impossible to think of all the access scenarios for resources in advance, especially in a dynamic environment, thus having a system that can generalise from examples to cases it hasn’t seen before is very useful. The idea is that this advisor would be like a second opinion on rule based or human decisions that can also be used in case of conflict or incomplete rule description. A slightly more detailed view of the advisor component can be seen in 2 where there is explicit mention of a context manager which provides the context used to asses the requests being made.
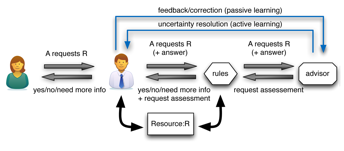
Figure 1: An overview of our Machine Learning enhanced access control system
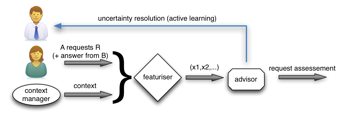
Figure 2: A more detailed view of the steps following a request in our Machine Learning enhanced access control system from the advisor’s perspective
The personal health record (PHR) problem is a possible applications for such a system. The personal health record problem is concerned with the access control of privacy records in a (network of) hospital(s). We assume the records are held within the hospital network and Bob is the security supervisor. The rules in the rules component can be based on national privacy rules and/or hospital specific rules and/or rules from the patient associated with the resource. Rules can potentially be the same for all instances of the access control system while the advisor is specific to each resource. Alice is a member of staff in the hospital and wants to get access to a patient’s record R. Usually, the request is made directly to the rules component and based on its decision the resource is granted or not as explained above. Of course there needs to be additional features such as break glass security so that a human can always override an automated decision in case of emergency by accepting to be accountable for breaking the said glass.
We are interested in the cases where the cost of a false positive or false negative prediction is outweighed by the overall benefit brought by the automation of a task or when the prediction is used as an indication or decision support rather than for decision making. In this setting, we are specifically concerned with the long term integration of such solutions in real environments which tend to evolve through time especially if humans are involved. Long term integration of learning in live environments poses two challenges. First, the concept drift [WK96] (the evolution of the tasks to be learned through time) that is naturally present in environments or tasks involving humans and second, the practical impossibility of consciously constantly training a learner from the supervisor’s point of view. To cope with the these two issues we propose to use semi-autonomous learner(s), either online (incremental) or offline with re-training, combined with infrequent supervisory ground truth to guide it (them), i.e. semi-supervised techniques.
We are unaware of other research proposing to treat an access control problem as we do. The closest applications that share our type of approach is a semi supervised classification problem of the Enron email corpus dataset, that takes into account sudden drift but also creation of new classes online [MK10].
A second application with similar traits to ours deals with semi-supervised anomaly detection of requests in webpages [MRKV09], the authors acknowledge that in order to be useful in practice an anomaly detection system needs to evolve as the environment does. They also propose to use semi-supervised learning with the exception that labels are given by a static rules thus not directly by a human supervisor.
Research Achievements to date
- Thorough literature review of Machine-Learning applied to security with an emphasis on semi-supervised techniques and their application to cope with concept drift.
- Implementation of a tool to generate datasets with customisable concept drifts. Using a simulation type approach is it particularly useful to produce datasets where real-life examples are not available or would be costly to produce.
- Conference paper in review, introducing the above mentioned tool and an example application for continuous body-sensor activity recognition.
References
[MR10]: J. STEFANOWSKI M. KMIECIAK. Batch weighted ensemble for mining data streams with concept drift. In In proc. of KKNTPD 2010, 2010
[MRKV09]: Federico Maggi, William Robertson, Christopher Kruegel, and Giovanni Vigna. Protect- ing a moving target: Addressing web application concept drift. In Proceedings of the 12th International Symposium on Recent Advances in Intrusion Detection, RAID ’09, pages 21–40, Berlin, Heidelberg, 2009. Springer-Verlag.
[WK96]: Gerhard Widmer and Miroslav Kubat. Learning in the presence of concept drift and hidden contexts. Machine Learning, 23(1):69–101, 1996.
Personal Website: http://www.icarenet.eu/fellows/Jeremiah
Collaborations:
- Eindhoven University of Technology
- Lancaster University
